
Ann Arbor startup and TechDisrupt 2019 AI top pick Voxel51 just announced that it has just launched a new tool called FiftyOne, the computer vision industry's first open-source tool for experimenting with and cleaning image and video data for machine learning. Engineers working with machine learning for image and video data sets have a new way of inspecting their data for labeling errors and finding explanations for functional problems emerging from the data. It's a quicker solution to the problem of cleaning datasets, which grows by the year along with the size of datasets available for machine learning applications.
“Nothing hinders the success of machine learning systems more than poor-quality data. Yet the process of continuous data quality management is incredibly challenging and time consuming,” says Jason Corso, Voxel51 co-founder and CEO. “We created this tool... to offer engineers a better toolbox and a more efficient way to improve the quality, accuracy and diversity of image datasets in order to mitigate the consequences of bad data and to improve the predictive performance of production models.”
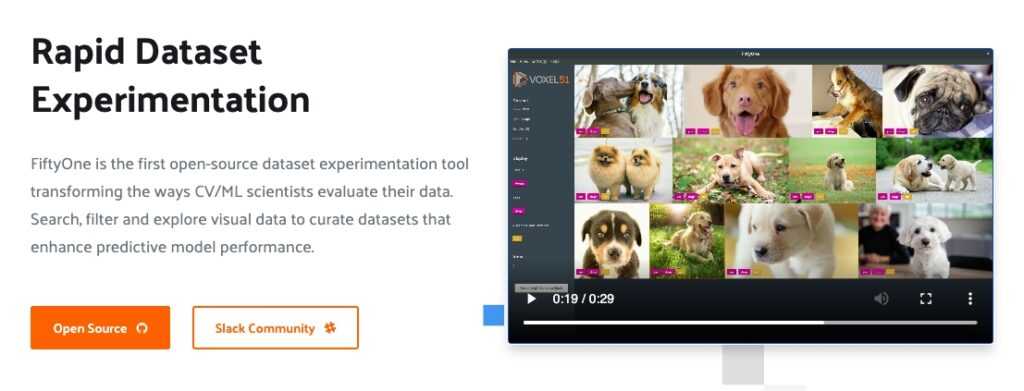
Available now at voxel51.com, the new tool enables computer vision and machine learning scientists to rapidly experiment with data sets to find problems hiding in their datasets. "Fifteen years ago we only had dozens of images to work with in machine learning," Corso explains. "Now in the era of deep learning we have thousands to millions. It has become burdensome to look at the data."
It works like this: FiftyOne is a developer tool that functions as an IDE for the data components of machine learning. When you're doing machine learning for photo or video, you work within the FiftyOne tool to examine your data to flag duplicate or mislabeled images in your data set, or to execute queries with a single line of code to figure out why a certain system is failing. For example, Corso says, "If I'm building an autonomous driving algorithm it has to identify pedestrians. Say the performance is 80%. But it won't be even. It might detect all pedestrians at one intersection, and fail more at others. Our tool helps you inquire with one line of code to figure out that when it's raining, the system fails."
Developers who are already looking at data sets for these problems can work more easily through rapid data set experimentation. "Machine learning engineers know they should do this," Corso explains, "but sometimes they might have to write 50 lines of code for each scenario they're exploring. This makes it easier to do what they know they should be doing."

ML Data Problems That Can Be Solved by FiftyOne
Here are some problems that can crop up with machine learning data that can be addressed by the FiftyOne tool:
Labeling Images: If your data set has mistakes, such as trucks annotated as buses, you will create a performance failing. By examining your data set for duplicate or mislabeled images, you can clean up the image labeling.
Incorrect Instructions: If you give incorrect or vague instructions on how to label images, errors will be baked into your data set through mistakes such as partially occluded objects in images that are mislabeled. The FiftyOne tool makes it easier to see problems like this and address them.
Representative Data Sets: Through getting close to a data set, you can also see problems of representation. Some classes of objects might be well represented, while others are not. If you have 1000 images of pants and shirts, and only 50 images of hats, you can see you need to add more hat images to your data set for optimum performance.
Image Size: Sizes of objects can also be an issue. If your system performs well whenever road sign images are large but not when they are small or distant, you need more data with small or distant sign images. The FiftyOne tool also makes it easier to identify these types of problems so they can be addressed.
![]()
Open-Source Machine Learning
Where does Voxel51 go from here? The FiftyOne tool is open source, according to Corso, so the company is looking for interested parties to submit feature requests and bug reports on how the tech is functioning.
Corso says that FiftyOne "emphasizes the role data plays in the machine learning life cycle. Another company recently released a similar tool, Nucleus by Scale.ai, and we take this to mean the space is heating up."
Cleaning Up Bias?
It has already proved problematic that facial recognition software is not properly equipped with adequate data to ID minorities, which can create problems with policing and the potential for wrongful arrests. Implicit bias baked into a system by the subconscious prejudice of programmers is another problem getting a lot of recent attention. And all of this has pointed in one direction for solutions: machine learning is only as good as its data. So what can be done to help clean uneven data sets and implicit bias from machine learning? Corso says Voxel51 is conservative about claiming anything regarding solving bias, but tools like FiftyOne provide the ability to solve bias problems if engineers are looking in the right places. There is broad application for these tools. FiftyOne does not flag or root out particular problems regarding bias, per se, but it does give an access point for engineers doing the difficult work of cleaning or shoring up inadequate data sets to address social problems as well as engineering ones.
Corso says there is another problem beyond subconscious bias and uneven data in machine learning, and that is that people are rewarded for creating technology to process data in new ways, but aren't rewarded necessarily for doing a good job of cleaning up data. "In the machine learning space you create new methods of processing existing data," he says, "not by changing the data. There is a mismatch in what's rewarded. That needs to evolve."
We are looking forward to hearing more about where machine learning tools take this space in an era of more awareness that tools can't accomplish much without healthy data. To learn more about FiftyOne, you can join the FiftyOne Slack community or check out the workflows and tutorials here.